
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 논문
- 참조자
- algorithm #알고리즘 #백준
- 프로그래머스
- 2020.02.23
- 알고리즘연습
- Overloading
- ComputeShader
- rendering pipeline
- Implicit method
- ppt
- 독서
- 2020.03.16
- oprerator
- Conjugate Gradient
- stretch force
- 알고리즘
- C++
- C
- 백준
- sparse matrix
- 학습용
- game jam
- Til
- UNORDERED_MAP
- graphics
- class
- Algorithm
- TIP
- numerical method
Archives
- Today
- Total
OSgood의 개발일기
GPU Architecture & Compute Shader 본문
💡
아래 발표 자료를 번역 및 해석한 내용입니다.
GPU Architecture & Compute Shader - Carlos Fuentes
개인적인 요약
배경 지식
- 픽셀 스레드(Thread): 가장 기본적인 실행 단위
- 워프(Warp): 동시에 실행되는 스레드 그룹 (NVIDIA에서는 일반적으로 32개 스레드)
- 블록(Block): 여러 워프의 집합
- 그리드(Grid): 여러 블록의 집합
요약




1. GPU 아키텍처 기본 구조
첫 번째 다이어그램은 GPU의 기본 계층 구조를 보여줍니다:
- GPU는 크게 NVIDIA와 AMD 아키텍처로 나뉩니다.
- NVIDIA는 SM(Streaming Multiprocessor)을 사용하고, 그 안에 워프(32개 스레드)가 있습니다.
- AMD는 CU(Compute Unit)를 사용하고, 그 안에 웨이브프론트(64개 스레드)가 있습니다.
- 최종적으로 각 스레드는 개별 픽셀/버텍스를 처리합니다.
2. GPU 처리 흐름
두 번째 다이어그램은 GPU에서 픽셀이 처리되는 전체 흐름을 보여줍니다:
- 픽셀/버텍스가 블록으로 패킹됩니다.
- 블록이 CU/SM으로 전송됩니다.
- CU/SM 내에서 웨이브/워프로 분할됩니다.
- 활성 웨이브가 실행됩니다.
- 메모리 지연이 발생하면 다른 웨이브로 전환합니다.
- 메모리 지연이 없으면 계속 실행합니다.
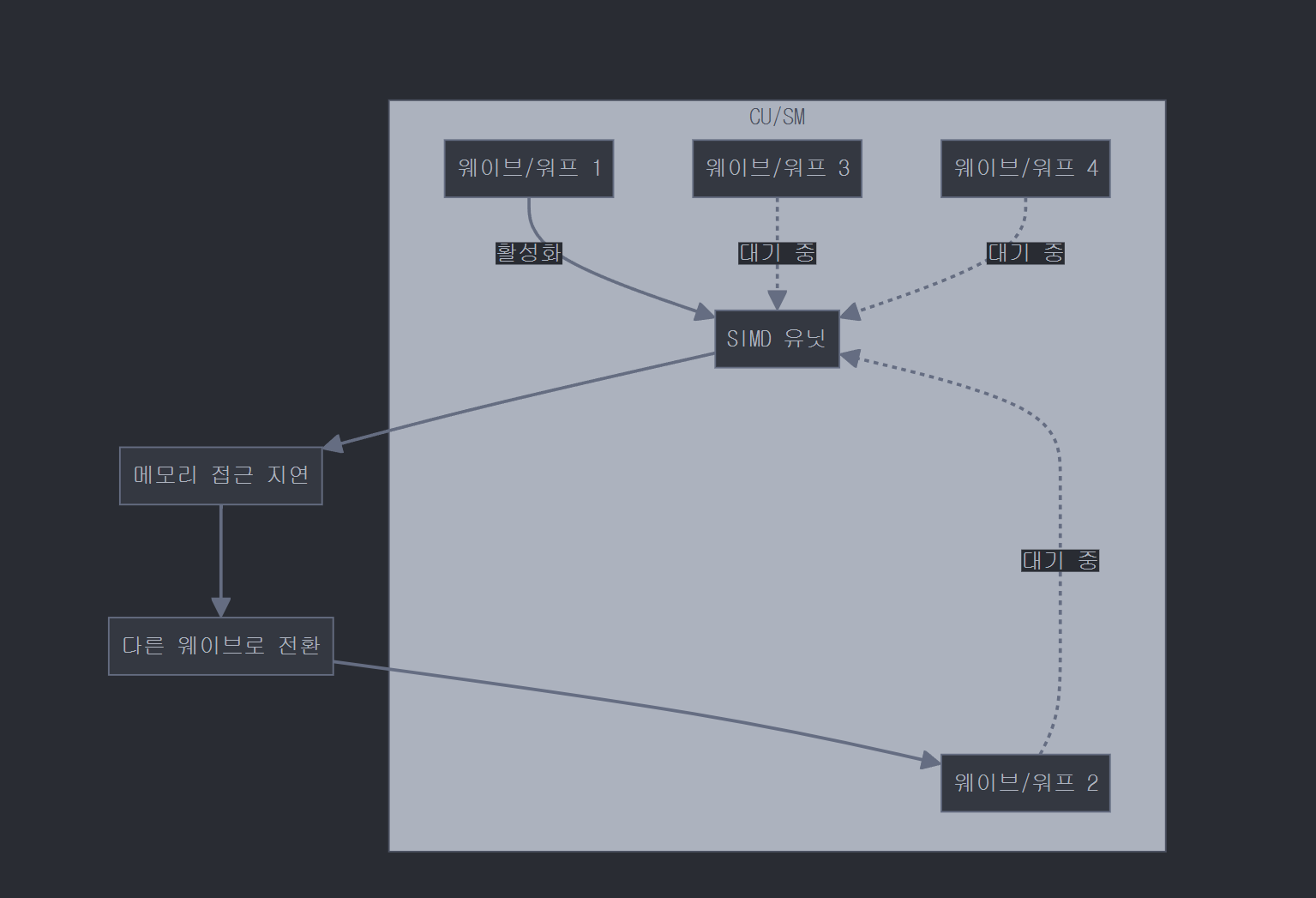
3. GPU 실행 개념
세 번째 다이어그램은 CU/SM 내부에서 웨이브/워프가 실행되는 방식을 보여줍니다:
- CU/SM 내부에는 여러 웨이브/워프(1, 2, 3, 4)가 있습니다.
- 한 번에 하나의 웨이브만 SIMD 유닛에서 활성화되어 실행됩니다(웨이브 1).
- 다른 웨이브들은 대기 상태입니다.
- 활성 웨이브가 메모리 접근 지연이 발생하면, 다른 웨이브(웨이브 2)로 전환됩니다.
본문 내용
CPU Stage
- CPU는 OpenGL API를 통해 명령을 발행하고 동기적으로 실행되기를 기대합니다.
- 드라이버는 이러한 명령을 명령 큐에 넣고 GPU에 비동기적으로 전달합니다(이전 명령과의 종속성이 없는 경우).
- 그림은 CPU가 여러 Draw 명령(Draw 0~3)을 실행하는 동안 GPU가 약간의 지연 후에 이러한 명령을 처리하는 방식을 보여줍니다.
- CPU는 그래픽 명령을 처리하면서 동시에 물리, 애니메이션, 게임플레이 계산도 수행합니다.

Driver Stage
- 드라이버는 애플리케이션으로부터 명령을 받아 GPU 명령으로 변환하고 명령 버퍼에 넣습니다.
- 명령 버퍼는 CPU와 GPU가 독립적으로 작동할 수 있게 해줍니다.
- 명령 버퍼는 FIFO(First In, First Out) 방식으로 작동하여 동기성을 유지합니다.
- 아래 그림은 CPU(애플리케이션)에서 GPU로 명령이 전달되는 과정을 보여줍니다. 명령 버퍼에는 텍스처 설정, 블렌딩 사용, 셰이더 설정, VBO 설정, 그리기 등의 명령이 포함됩니다.

GPU Stage
- 명령 읽기() 단계: 명령을 읽어서 사용 가능하게 만듭니다.
- 데이터 가져오기(Data fetch) 명령: 일부 명령은 데이터를 포함하거나 데이터를 복사하는 명령입니다.
- GPU에는 RAM(CPU 메모리)에서 VRAM(GPU 메모리)으로 데이터를 복사하는 전용 엔진이 있습니다.
- 이 데이터에는 텍스처, 정점 버퍼, 셰이더 버퍼 객체 등이 포함됩니다.
- 이 시점 이후에는 그리기에 필요한 모든 것이 준비되어 있어야 합니다.
GPU architecture history
- 그리기 명령이 어떻게 작동하고 셰이더가 어떻게 실행되는지 이해하기 위해서는 GPU 하드웨어 아키텍처와 그 역사를 이해해야 합니다.
- 첫 3D 그래픽 카드인 Voodoo2(~1998년)는 셰이더가 없었고, 래스터라이저와 두 개의 텍스처 유닛을 가지고 있었습니다.
- 셰이더의 등장 이후에 초기 카드들은 정점 유닛과 픽셀 유닛이 분리되어 있었습니다.
GPU architecture history
- 정점 유닛은 처리할 정점을 메모리(속성 버퍼)에 기록하고, 픽셀 유닛이 이를 소비했습니다.
- 두 유닛은 비슷한 계산 능력을 가졌지만 메모리 접근 요구사항이 달랐습니다:
- 텍스처 유닛은 픽셀 유닛만 접근 가능했습니다.
- 텍스처 접근은 가장 메모리 대역폭을 많이 요구하는 작업이었습니다.
- 그림은 정점 유닛, 속성 버퍼, 픽셀 유닛, 텍스처 유닛 간의 데이터 흐름을 보여줍니다.

GPU architecture history
- 당시에는 정점 유닛이 픽셀 유닛보다 적었습니다. 게임이 많은 픽셀을 차지하는 큰 삼각형을 사용했기 때문에 이는 최적의 구성이었습니다.
- 그러나 게임이 발전하면서, 일부는 더 복잡한 형상을 렌더링하기 위해 더 많은 정점 처리 능력이 필요했고, 다른 게임들은 더 복잡한 픽셀 셰이더를 작성하기 시작했습니다.
- 이러한 상황에서 정점 및 픽셀 유닛의 고정 분포는 그들 사이의 부하 균형을 허용하지 않았기 때문에 충분히 좋지 않았습니다( In this scenario, a fixed distribution of vertex and pixel units wasn’t good enough because it didn’t allows a load balancing between them).
GPU architecture history
- 2006년 후반에 통합된 정점 및 픽셀 유닛을 가진 새로운 GPU 아키텍처가 시작되었습니다.
- 유닛 간의 구분이 제거되었습니다: 모든 유닛이 텍스처 메모리에 접근할 수 있고, 데이터는 속성 버퍼 메모리를 통해 그들 사이에 전달될 수 있습니다.
- 그림은 속성 버퍼, 통합된 정점 및 픽셀 유닛, 텍스처 유닛 간의 연결을 보여줍니다.

GPU architecture history
- 이 아키텍처 덕분에 GPU를 일반 목적 계산(GPGPU)에 사용하기 시작했습니다: 물리 시뮬레이션, 컴퓨터 비전, 천체 물리학 등.
- 이 통합 아키텍처는 속성 버퍼가 실제로는 로컬(또는 공유) 메모리이고 텍스처 유닛은 글로벌 메모리인 일반적인 구조로 볼 수 있습니다.
- 그림은 로컬 메모리, 컴퓨트 유닛, 글로벌 메모리 간의 관계를 보여줍니다.

Compute units
- 컴퓨트 유닛(CU)은 여러 산술 연산을 동시에 처리하는 유닛입니다.
- 셰이더는 정점 변환이나 조명 알고리즘과 같은 산술 연산을 많이 사용하는 프로그램이기 때문에 이것이 의미가 있습니다.
- 각 CU는 여러 SIMD 유닛을 포함합니다.
- SIMD(Single Instruction Multiple Data)는 16개의 서로 다른 요소에 대해 동시에 동일한 산술 명령을 실행할 수 있는 유닛입니다.
SIMD units
- 16개 요소(SIMD 레인이라고 함)는 정확히 한 클록 사이클에 실행되지 않고, 약간의 지연이 있습니다. 예를 들어 AMD GCN 아키텍처에서는 4 사이클의 지연이 있습니다.
- AMD 아키텍처에서 CU는 4개의 SIMD 유닛을 가지고 있어, 각 CU는 사이클당 64개 명령을 계산할 수 있습니다(실제로는 4 사이클마다). NVIDIA 아키텍처에서는 32개입니다.
- 그림은 웨이브프론트(64 작업 항목)가 여러 사이클에 걸쳐 Add 및 Mul 연산을 통해 처리되는 방식을 보여줍니다.

SIMD vector operations
- 전통적인 3D 애플리케이션은 벡터 연산에 관한 것이었습니다:
- 정점 셰이더의 벡터 및 법선과 같은 속성은 벡터 및 행렬 곱셈을 포함하며, 이는 실제로 벡터와 벡터의 내적(종종 4 구성 요소 요소로 표현됨)입니다.
- 프래그먼트 셰이더의 조명도 법선, 광 방향 등의 벡터 연산이 필요했습니다.
- 그래서 초기 GPU는 SIMD 유닛을 사용하여 벡터 연산을 구현했습니다.

SIMT
- 게임이 발전함에 따라 셰이더에서 더 많은 스칼라 연산이 필요해져, SIMD 유닛의 이론적 처리량을 벡터 연산만으로 실현하기 어려워졌습니다.
- 그래서 SIMT(Single Instruction Multiple Threads)라는 새로운 패러다임이 등장했습니다.
- 이 아이디어는 정확히 동일한 명령을 실행하는 여러 스레드를 사용하여 SIMD 유닛에 각각의 연산을 공급하는 것입니다.
- SIMT는 GPU의 병렬성이 많은 수의 다른 데이터(정점, 프래그먼트 등)에 대해 동일한 셰이더를 실행해야 한다는 사실을 활용합니다.
Waves/Warps
- GPU가 렌더링 명령을 실행할 때, 모든 정점/픽셀에 대한 스레드를 생성하고 이를 블록으로 패키징하여 컴퓨트 유닛에 분배합니다.
- 컴퓨트 유닛은 이 블록을 웨이브(AMD) 또는 워프(NVIDIA)라고 불리는 더 작은 블록으로 나눕니다. 이 크기는 CU가 사이클당 실행할 수 있는 연산 수와 정확히 같습니다(AMD는 64, NVIDIA는 32).
- 오른쪽 그림은 웨이브 내의 여러 스레드를 보여줍니다.

Wave lockstep execution
- GPU가 렌더링 명령을 실행할 때, 모든 정점/픽셀에 대한 스레드를 생성하고 이를 블록으로 패키징하여 컴퓨트 유닛에 분배합니다.
- 컴퓨트 유닛은 이 블록을 웨이브(AMD) 또는 워프(NVIDIA)라고 불리는 더 작은 블록으로 나눕니다. 이 크기는 CU가 사이클당 실행할 수 있는 연산 수와 정확히 같습니다(AMD는 64, NVIDIA는 32).
- 오른쪽 그림은 웨이브 내의 여러 스레드를 보여줍니다.
Lockstep control flow
- 분기(if, while, loop)가 웨이브의 다른 스레드에 대해 다를 수 있는 경우, 록스텝 실행이 어떻게 제어 흐름을 구현하는지에 대한 질문이 제기됩니다.
- GPU는 프레디케이션을 사용하여 분기를 해결합니다:
- 분기의 양쪽 모두 실행됩니다.
- 비트마스크(스레드당 하나의 비트)가 조건의 결과를 저장합니다. 비트가 1이면 스레드가 활성화되고, 그렇지 않으면 이 스레드에서 실행되는 것은 모두 버려집니다.
CU architecture recap
결과적으로 GPU는 다음을 포함하는 많은 CU(AMD RDNA3는 약 30-100개)를 가지고 있습니다:
- 명령을 실행하는 일부 SIMD 프로세서
- SIMD는 많은 항목(정점, 프래그먼트)에 걸쳐 록스텝으로 하나의 명령을 실행합니다.
- 셰이더 단계 간에 데이터를 통신하는 데 사용되는 로컬 메모리
- 텍스처와 같은 데이터를 위한 글로벌 메모리

CU architecture recap
- 컴퓨트 유닛은 다양한 유형의 메모리에 접근할 수 있습니다:
- 레지스터: 셰이더 변수 저장에 사용
- 로컬 메모리: 셰이더 단계 간 속성 통신에 사용
- 유니폼 및 유니폼 버퍼 객체도 여기에 저장됩니다.
- 글로벌 메모리: 지연을 피하기 위한 2단계 캐시가 있습니다.
- 텍스처 및 셰이더 스토리지 버퍼 객체가 여기에 저장됩니다.
- 이 구성은 SIMD 레인에 데이터를 공급하는 데 필요한 대역폭을 제공하지만, 글로벌 메모리의 지연 시간은 매우 높습니다.
- 표는 대역폭, 지연 시간, 용량 간의 관계를 보여줍니다.
Latency hiding
- GPU는 픽셀/정점을 블록으로 패키징하여 CU로 보냅니다.
- CU는 이들을 다시, 웨이브로 나누어 실행합니다.
- 주어진 시간에 활성화(실행 중)된 웨이브는 하나뿐입니다.
- 글로벌 메모리 지연을 숨기기 위해 CU는 메모리를 기다리는 활성 웨이브의 실행을 일시 중단하고 그 동안 실행할 수 있는 다른 웨이브로 전환할 수 있습니다.
- 블록의 웨이브 수는 셰이더 복잡성에 따라 달라지며, 이를 점유율(Occupancy)이라고 합니다(AMD GCN은 최대 40개까지 가질 수 있습니다).
- 그림은 점유율이 2인 경우를 보여줍니다.

Context switch and registers
- 웨이브 전환은 지연을 효율적으로 숨기기 위해 즉각적이어야 합니다.
- 전환은 셰이더 상태(변수 값, PC)를 메모리에 복사하고 다시 읽는 것을 의미합니다.
- 즉각적으로 수행하기 위해 복사 대신 상태를 레지스터에 상주시킵니다.
- 이를 위해 많은 레지스터가 필요합니다.
- AMD GCN의 단일 CU는 레지스터인 256KiB의 메모리를 포함합니다.
- 따라서 GPU가 점유율을 줄여야 하기 전에 256 KiB/(40 * 4 바이트 * 64 스레드) = 25 레지스터를 사용할 수 있습니다.
Memory, latency and programming style
- 메모리와 GPU가 지연을 숨기는 방법을 고려하면, 높은 점유율과 글로벌 메모리 접근 지연을 숨길 수 있는 더 많은 기회를 갖기 위해 유지해야 할 상태의 양을 최소화해야 합니다.
- 그러나 셰이더가 글로벌 메모리 접근이 없는 경우(거의 모든 산술 연산인 경우), SIMD 레지스터의 100%를 차지하는 단일 웨이브를 가질 수 있습니다.
- 또한 로컬 메모리와 글로벌 메모리 캐시를 최대한 활용해야 합니다. 이들의 대역폭과 지연 시간이 글로벌 메모리보다 더 좋기 때문입니다.
General Purpose Computation on GPU
- 현재 GPU 아키텍처는 렌더링뿐만 아니라 GPU에서의 범용 계산(GPGPU)에도 사용할 수 있습니다.
- GPU는 부동 소수점 계산에 좋기 때문에 다음과 같은 문제 유형을 해결하는 데 좋은 옵션으로 간주됩니다:
- 물리 시뮬레이션
- 디지털 이미지 처리
- 비디오 처리
- 그러나 CPU용으로 설계된 알고리즘을 GPU용으로 작성하는 것은 간단하지 않습니다.
GPGPU Languages
- 렌더링 파이프라인을 사용할 필요가 없는 애플리케이션을 위한 GPGPU 코드를 작성하기 위한 언어가 있습니다:
- OpenCL(Khronos에서 만든 개방형 컴퓨팅 언어)
- CUDA(NVIDIA에서 만든 컴퓨트 통합 장치 아키텍처)
- OpenGL 버전 4.3은 OpenGL과 통합된 범용 컴퓨팅을 사용할 수 있는 셰이더 단계로 컴퓨트 셰이더를 도입했습니다:
- 렌더링 파이프라인과 동일한 OpenGL 컨텍스트를 공유합니다.
- 컴퓨트와 렌더링 파이프라인의 다른 단계 간에 리소스를 공유할 수 있습니다.
Compute shaders
- 컴퓨트 셰이더를 사용하면 GPU 하드웨어 아키텍처를 활용하는 범용 프로그램을 만들 수 있습니다.
- 컴퓨트 셰이더는 렌더링 파이프라인의 일부가 아닙니다.
- 컴퓨트 셰이더는 범용 프로그램으로서 자체 데이터 공간, 입력 및 출력을 정의합니다.
- OpenGL 함수를 사용하여 이 데이터에 대해 수행될 병렬 실행 수를 정의합니다.
Work groups
- 작업 도메인(전체 데이터 공간)이 있다고 가정하면, 컴퓨트 유닛을 효율적으로 사용하기 위해 작업 도메인을 워크 그룹(렌더링 파이프라인에서 만든 픽셀/정점 블록과 동등)으로 분할하고자 합니다.
- 이 워크 그룹은 컴퓨트 유닛에 분배됩니다.
- 컴퓨트 유닛은 이 워크 그룹을 서브그룹(렌더링 파이프라인의 웨이브)으로 분할합니다.
- 마지막으로, 워크 그룹의 각 단일 요소를 워크 아이템(렌더링 파이프라인의 스레드)이라고 합니다.
Work groups constraints
- 각 워크 그룹은 서로 독립적으로 작동합니다. 이는 다음 사실에 의존할 수 없음을 의미합니다:
- 동일한 도메인의 다른 워크 그룹이 실행 중입니다.
- 워크 도메인 내의 워크 그룹이 특정 순서로 실행됩니다.
- 동일한 워크 그룹의 워크 아이템을 동기화하는 명령이 있으며, 이들은 로컬 메모리를 통해 데이터를 교환할 수 있습니다.
- 이 모델은 모든 컴퓨트 셰이더 API에서 동일합니다.
Work groups and GPU architecture mapping
- GPU 아키텍처 측면에서, 우리의 작업 도메인은 컴퓨트 유닛에서 실행되는 워크 그룹으로 구성되며, 각 SIMD 레인은 다른 워크 아이템을 처리합니다.
- 예: 이미지의 모든 픽셀을 빨간색으로 설정하는 컴퓨트 프로그램. 작업 도메인은 이미지이고, 워크 그룹은 이미지의 하위 분할(예: 8x8 픽셀)입니다.

'Graphics' 카테고리의 다른 글
| Rendering pipeline (0) | 2020.02.24 |
|---|
'Graphics' Related Articles
more

Comments